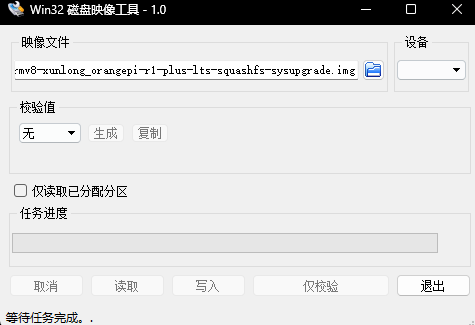
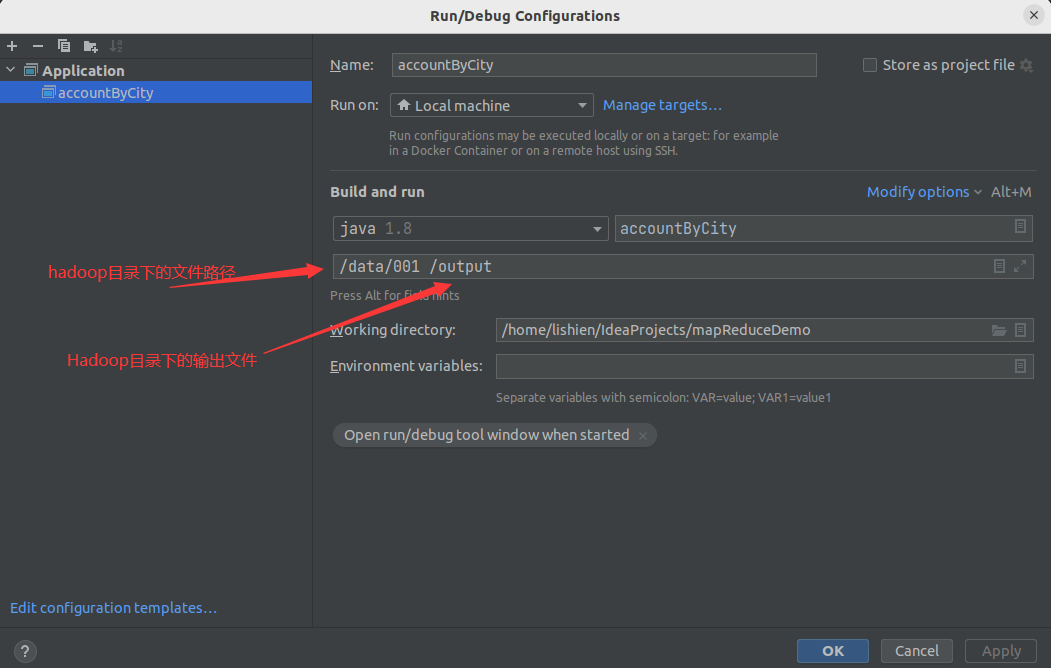
/** * Builder for a ReferenceGlobalRootComponent. */ @Component.Builder interface Builder extends GlobalRootComponent.Builder { ReferenceGlobalRootComponent build(); }
/** * Builder for a {@link ReferenceSysUIComponent}, which makes it a subcomponent of this class. */ ReferenceSysUIComponent.Builder getSysUIComponent(); //通过获取副组件构造器的方式确定父子关系 }
// Stand up WMComponent setupWmComponent(mContext); // 初始化 mWMComponent
// And finally, retrieve whatever SysUI needs from WMShell and build SysUI. SysUIComponent.Builderbuilder= mRootComponent.getSysUIComponent(); // 将WMShell 模块核心依赖添加到 ApplicationSingeton scope中 if (initializeComponents) { // Only initialize when not starting from tests since this currently initializes some // components that shouldn't be run in the test environment builder = prepareSysUIComponentBuilder(builder, mWMComponent) .setShell(mWMComponent.getShell()) .setPip(mWMComponent.getPip()) .setSplitScreen(mWMComponent.getSplitScreen()) .setOneHanded(mWMComponent.getOneHanded()) .setBubbles(mWMComponent.getBubbles()) .setTaskViewFactory(mWMComponent.getTaskViewFactory()) .setShellTransitions(mWMComponent.getShellTransitions()) .setKeyguardTransitions(mWMComponent.getKeyguardTransitions()) .setStartingSurface(mWMComponent.getStartingSurface()) .setDisplayAreaHelper(mWMComponent.getDisplayAreaHelper()) .setRecentTasks(mWMComponent.getRecentTasks()) .setBackAnimation(mWMComponent.getBackAnimation()) .setDesktopMode(mWMComponent.getDesktopMode());
// Only initialize when not starting from tests since this currently initializes some // components that shouldn't be run in the test environment mWMComponent.init(); } else { ...... } mSysUIComponent = builder.build(); // 实例化Component,(生成依赖关系图)
// Every other part of our codebase currently relies on Dependency, so we // really need to ensure the Dependency gets initialized early on. Dependencydependency= mSysUIComponent.createDependency(); dependency.start(); // 初始化全局仓库 }
// Start all of SystemUI ((SystemUIApplication) getApplication()).startSystemUserServicesIfNeeded();
...... }
//SystemUIApplication
publicvoidstartSystemUserServicesIfNeeded() { if (!shouldStartSystemUserServices()) { Log.wtf(TAG, "Tried starting SystemUser services on non-SystemUser"); return; // Per-user startables are handled in #startSystemUserServicesIfNeeded. } final String vendorComponent = mInitializer.getVendorComponent(getResources());
// Sort the startables so that we get a deterministic ordering. // TODO: make #start idempotent and require users of CoreStartable to call it. Map<Class<?>, Provider<CoreStartable>> sortedStartables = newTreeMap<>( Comparator.comparing(Class::getName)); sortedStartables.putAll(mSysUIComponent.getStartables()); // 获取所有Corestartabe sortedStartables.putAll(mSysUIComponent.getPerUserStartables()); startServicesIfNeeded( sortedStartables, "StartServices", vendorComponent); //启动服务的核心方法 }
/** Called to determine if the dumpable should be registered as critical or normal priority */ defaultbooleanisDumpCritical() { returntrue; }
/** Called immediately after the system broadcasts * {@link android.content.Intent#ACTION_LOCKED_BOOT_COMPLETED} or during SysUI startup if the * property {@code sys.boot_completed} is already set to 1. The latter typically occurs when * starting a new SysUI instance, such as when starting SysUI for a secondary user. * {@link #onBootCompleted()} will never be called before {@link #start()}. */ defaultvoidonBootCompleted() { } }
@SysUISingleton open classBroadcastDispatcher@Inject constructor( private val context: Context, @Mainprivate val mainExecutor: Executor, @BroadcastRunningprivate val broadcastLooper: Looper, @BroadcastRunningprivate val broadcastExecutor: Executor, private val dumpManager: DumpManager, private val logger: BroadcastDispatcherLogger, private val userTracker: UserTracker, private val removalPendingStore: PendingRemovalStore ) : Dumpable {
在启动Corestartable前将会先实例化,在实例化过程中由dagger
打个比方,如果你是一个电脑生产工厂那么dagger就是你的工厂助理
1、如果你需要生产一台电脑,那么你将大致需要(依赖) CPU 内存 硬盘 主板 显卡 等等,你将这些依赖需求告知dagger
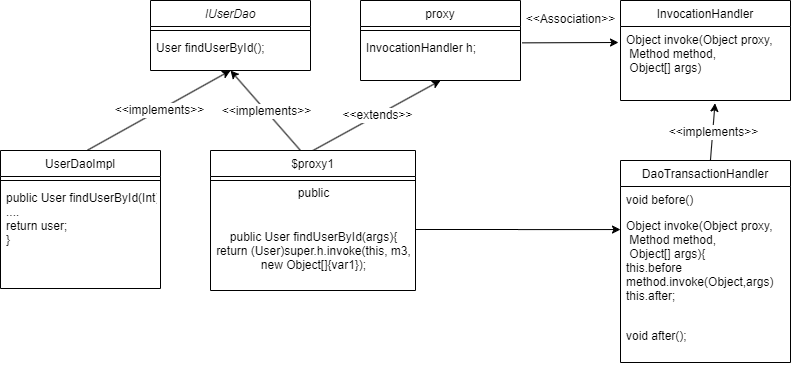
publicclassDaoTransactionHandlerimplementsInvocationHandler { // if other class want use proxy you can choose Object class private Object obj;
publicDaoTransactionHandler(Object obj) { this.obj = obj; } @Override public Object invoke(Object proxy, Method method, Object[] args)throws Throwable { Objectres=null; // if you want to enhance just only one method if ("findUserById".equals(method.getName())) { this.before(); res = method.invoke(obj,args); this.after(); }else { res = method.invoke(args); } return res; }
privatevoidbefore() { System.out.println("turn on enhance transaction"); } privatevoidafter(){ System.out.println("turn off enhance transaction"); } }
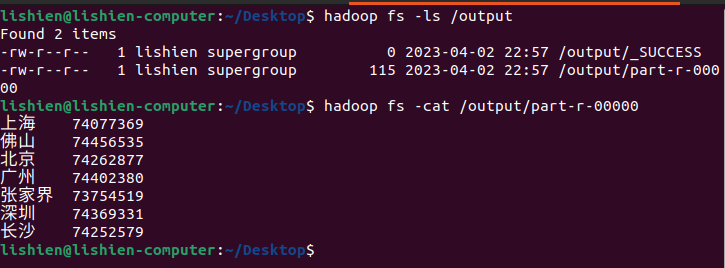
...... 23በ22:57:00 INFO mapred.LocalJobRunner: Finishing task:attempt_local524911839_0001_r_000000_0 23በ22:57:00 INFO mapred.LocalJobRunner:reducetaskexecutorcomplete. 23በ22:57:01 INFO mapreduce.Job:map100%reduce100% 23በ22:57:01 INFO mapreduce.Job:Jobjob_local524911839_0001completedsuccessfully 23በ22:57:01 INFO mapreduce.Job: Counters:35 ......
# Note: you need to be using OpenAI Python v0.27.0 for the code below to work import openai openai.api_key = '你的API' response = openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=[ # {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Who are you?"},#这里content表示输入问题 # {"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."}, # {"role": "user", "content": "Where was it played?"} ] ) print(response['choices'][0]['message']['content'])
3、结果显示
打印类似如下内容说明成功!
1
As an AI language model developed by OpenAI, I am not a person or a human being. I am a computer program designed to understand and generate natural language responses to interact with humans.