模拟电商日志mapRuce计算 准备环境
日志信息模拟生成 利用javaIO模拟生成100w条购买记录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 &20320230401170400&Larry&虚拟产品&68.0&3.0&204.0&北京 &66420230401170400&吴九&电脑&56.0&13.0&728.0&北京 &90620230401170400&郑十&牙刷&32.0&9.0&288.0&北京 &60020230401170400&郑十&毛巾&78.0&1.0&78.0&长沙 &23020230401170400&吴九&虚拟产品&61.0&17.0&1037.0&长沙 &70520230401170400&张三&鞋子&70.0&15.0&1050.0&上海 &44620230401170400&王五&牙刷&11.0&7.0&77.0&上海 &18320230401170400&赵六&篮球&48.0&3.0&144.0&上海 &61620230401170400&周八&牙刷&30.0&19.0&570.0&上海 ...... &80320230401170400&李四&水杯&19.0&9.0&171.0&北京 &48620230401170400&周八&牙刷&97.0&9.0&873.0&张家界 &43120230401170400&张三&篮球&36.0&6.0&216.0&佛山 &93720230401170400&李四&毛巾&56.0&19.0&1064.0&广州
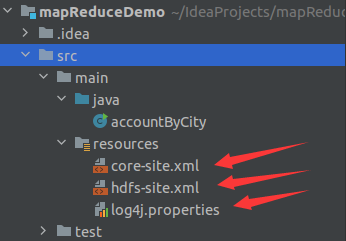
构建maven项目 项目结构:将hadoop/etc/hadoop目录下的core-site.xml,hdfs-site.xml,log4g.properties文件分别复制到resources目录下
修改pom.xml 配置文件(博主用的Hadoop2.10.1,jdk1.8 maven3.9)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 <?xml version="1.0" encoding="UTF-8" ?> <project xmlns ="http://maven.apache.org/POM/4.0.0" xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation ="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" > <modelVersion > 4.0.0</modelVersion > <groupId > org.example</groupId > <artifactId > mapReduceDemo</artifactId > <version > 1.0-SNAPSHOT</version > <repositories > <repository > <id > apache</id > <url > http://maven.apache.org</url > </repository > </repositories > <dependencies > <dependency > <groupId > junit</groupId > <artifactId > junit</artifactId > <version > 4.12</version > <scope > test</scope > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-common</artifactId > <version > 2.10.1</version > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-hdfs</artifactId > <version > 2.10.1</version > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-mapreduce-client-core</artifactId > <version > 2.10.1</version > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-mapreduce-client-jobclient</artifactId > <version > 2.10.1</version > </dependency > <dependency > <groupId > log4j</groupId > <artifactId > log4j</artifactId > <version > 1.2.17</version > </dependency > </dependencies > </project >
计算每个城市对应的购买总金额,accountByCity.java代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;import java.util.StringTokenizer;public class accountByCity { public static class myMapper extends Mapper <Object,Text, Text, LongWritable> { private final static LongWritable account = new LongWritable (); private Text city = new Text (); private long startTime; @Override protected void setup (Context context) throws IOException,InterruptedException{ super .setup(context); startTime = System.currentTimeMillis(); } @Override public void map (Object key,Text value, Context context) throws IOException,InterruptedException{ String msg = value.toString(); String[] list = msg.split(";&" ;); city.set(list[7 ]); double myDouble = Double.parseDouble(list[6 ]); long myLong = (long )myDouble; account.set(myLong); context.write(city,account); } protected void cleanup (Context context) throws IOException,InterruptedException { super .cleanup(context); long endTime = System.currentTimeMillis(); long duration = endTime - startTime; System.out.println(";MapperTime : " ;+ duration+ ";ms" ;); } } public static class myReduce extends Reducer <Text,LongWritable,Text,LongWritable> { private LongWritable result = new LongWritable (); private long startTime; @Override protected void setup (Context context) throws IOException,InterruptedException{ super .setup(context); startTime = System.currentTimeMillis(); } public void reduce (Text key, Iterable<LongWritable> values, Context context) throws IOException,InterruptedException{ int sum = 0 ; for (LongWritable val : values) { sum += val.get(); } result.set(sum); context.write(key,result); } @Override protected void cleanup (Context context) throws IOException,InterruptedException{ super .cleanup(context); long endTime = System.currentTimeMillis(); long duration = endTime - startTime; System.out.println(";ReducerTime :" ;+duration+"; ms" ;); } } public static void main (String[] args) throws Exception{ Configuration conf = new Configuration (); Job job = Job.getInstance(conf,";;accountByCity" ;); job.setJarByClass(accountByCity.class); job.setMapperClass(myMapper.class); job.setReducerClass(myReduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); FileInputFormat.addInputPath(job,new Path (args[0 ])); FileOutputFormat.setOutputPath(job,new Path (args[1 ])); FileSystem fs = FileSystem.get(conf); fs.delete(new Path (args[1 ]),true );
运行项目 首先启动Hadoop服务 start-all.sh
上传日志文件到Hadoop的hdfs文件关系系统 关于Hadoop shell指令上传日志文件
假设这是我的日志文件路径/hadoop/test
hadoop fs -mkdir /data创建一个data目录
hadoop fs -mkdir /output创建一个output目录
hadoop fs -put /hadoop/test /data上传文件到data目录下
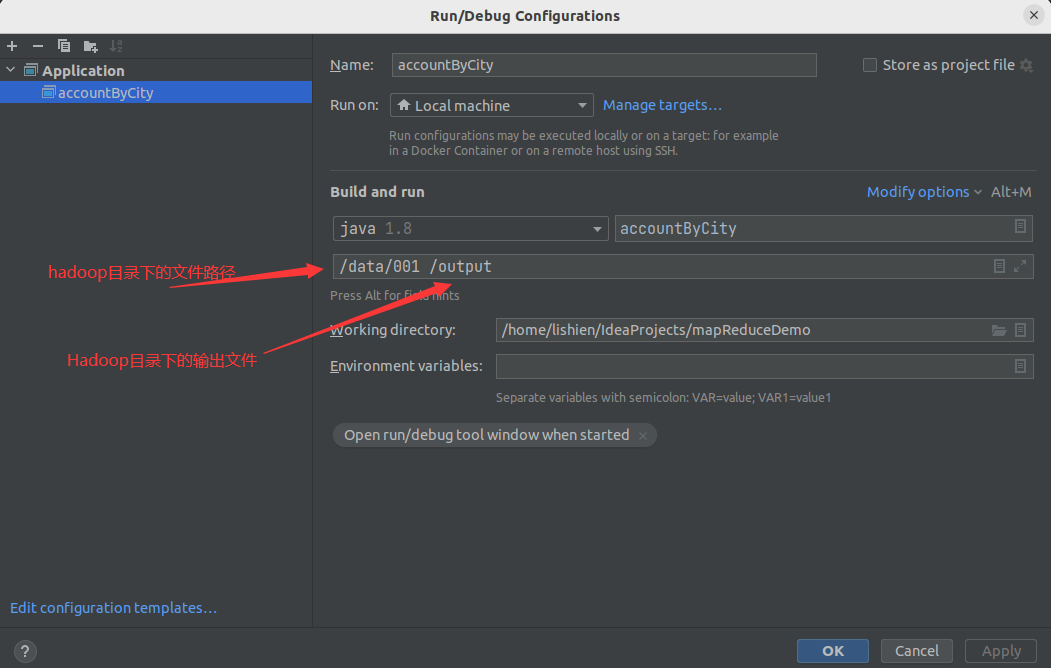
idea构建项目
执行项目 —success
map 100% reduce 100% 说明运行成功
1 2 3 4 5 6 7 8 ...... 23 በ 22:57:00 INFO mapred.LocalJobRunner: Finishing task: attempt_local524911839_0001_r_000000_0 23 በ 22:57:00 INFO mapred.LocalJobRunner: reduce task executor complete. 23 በ 22:57:01 INFO mapreduce.Job: map 100 % reduce 100 % 23 በ 22:57:01 INFO mapreduce.Job: Job job_local524911839_0001 completed successfully 23 በ 22:57:01 INFO mapreduce.Job: Counters: 35 ......
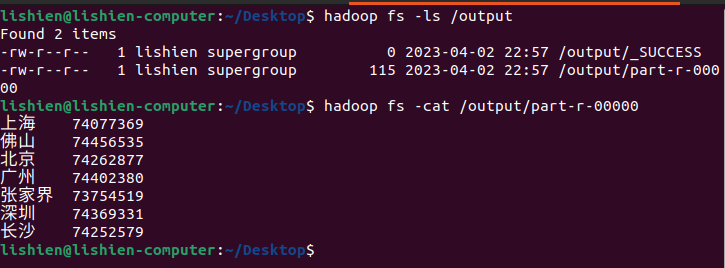
查看生成数据